Terraforming RDS — Part 2
Using modules with RDS
See Part 1 for the basics of RDS and Terraform. This post covers using Terraform with RDS and modules.
Keep in mind the abstraction layer stack from the previous post, modules can have a significant impact on how painful this is:

What is a module?
According to the Terraform documentation: “A module is a container for multiple resources that are used together.” Coming from a software background, I think of a module as a function with inputs (variables, in Terraform), outputs, and a lot of side effects. In software development, you try to minimize the side effects of a function, as they can surprise the caller, but in Terraform, the side effects are the whole point of a module.

Module best practices
Modules can be the most opaque layer of abstraction, behind which almost any magic can occur without the user being aware of it. For this reason, there are several best practices when using modules:
- Document the API and side effects. Make sure that it’s clear to the user of the module what values they can (or must) put in, what values they will get out, and what additional resources might be created or changed when they use the module.
- Use a separate GitHub repo. It is possible to create your module in the same repo as your other configuration, but then anyone can change the API or side effects of the module at any time and this will affect every use of the module, not just the one someone is updating the module for. HashiCorp also provides a module registry for useful community modules.
- Create release versions. Even in a separate repo, someone can change the module, so don’t just reference the master branch everywhere. By using release versions, you can update the module when you need to without affecting other usages until you are ready.
- Keep releases up-to-date. When someone makes a new release, make sure to update existing usages of the module as soon as is practical so that you get any benefits of the changes. Otherwise, instead of helping you keep things consistent and up to your standards, you’ll end up with a confusing mess of versions that do slightly different things.
# BAD
module "muffy-test-bad" {
source = "../modules/rds-instance" allocated_storage = 100
identifier = "muffy-test"
}# GOOD
module "muffy-test-good" {
source = "github.com/tf-mods/rds-instance?ref=v1.2.1" allocated_storage = 100
identifier = "muffy-test"
}
Note that modules can call other modules, so the layers of abstraction can get as deep as you are willing to go. Generally this is not a good idea, as it makes it extremely difficult to understand what is happening when you use the module, and even more difficult to modify a module which is depended on by other modules.
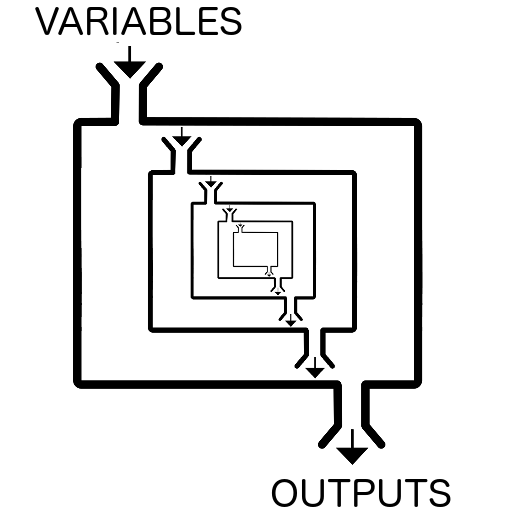
While I’m a big proponent of DRY in code, some amount of duplication is better than too many layers of abstraction in the case of Terraform.
Our RDS instance module
We have an RDS instance module which has accumulated a lot functionality over time:
- It configures our primary and replica databases, with configuration values computed based on the role of the instance
- It adds DataDog monitors for several different metrics on each database instance
- It creates a security group for each instance
- It creates an encryption key for each instance
It also used to create the parameter group, but this became extremely problematic to maintain, particularly as we changed versions of PostgreSQL and available parameters were added and removed, so we now manage parameter groups separately.
With so much functionality, the inner workings of the module have become increasingly difficult to understand.
“The module is broken”
As we created more databases, we started having errors every time we applied our Terraform:
Error: error modifying DB Instance (my-replica): InvalidParameterCombination: Both storage size and iops must be specified when modifying storage size or iops on an DB Instance that has iops
status code: 400, request id: bea26529-2d3d-4a18-b49d-6260cac45da9The engineers were understandably frustrated, particularly as it can take around an hour to create a database and this error does not show up until after the database is created. AWS, RDS, and Terraform are all heavily used across the industry, so it was reasonable to conclude that the thing which was unique to us was at fault. We started trying to determine what was wrong with our module.
terraform plan
The plan created when using the module looked fine. The error message says that both allocated_storageand iops must be specified in the API call, and both values were clearly specified in the plan:
+ resource "aws_db_instance" "rds-instance" {
+ allocated_storage = 16000
[...]
+ iops = 40000
[...]
+ replicate_source_db = "my-db"
[...]
}First step: Google
We googled the error message and found that there WAS problem with the AWS provider not sending both values— but it was fixed in 2016. It’s 2020 and we’re still seeing the same error.
What is going on here? After a lot of investigation, here’s what we found.
create-db-instance vs create-replica-db-instance
The API call to create a new primary database is create-db-instance.The API call to create a replica is create-replica-db-instance.The create replica call does not allow the--allocated-storage flag; it will always create the replica with exactly the same storage as the database being replicated.
The AWS provider understands all of this and makes the correct calls, but our module sends a value for allocated_storage which the provider therefore has to set aside while creating the replica.
modify-db-instance
After creating the instance, the AWS provider has this unapplied value for allocated_storage, so it tries to do precisely what we asked and specify the storage. To do this, it uses the AWS API call modify-db-instance with the argument--allocated-storage and the value we specified, even though this is the same value it already has from the primary.
This call can be found in CloudTrail:
"requestParameters": {
"dBInstanceIdentifier": "my-replica",
"allocatedStorage": 16000,
"vpcSecurityGroupIds": [
"sg-aabbccdd0099887766"
],
"applyImmediately": true,
"dBParameterGroupName": "my-replica-pg",
"preferredBackupWindow": "06:30-07:30",
"preferredMaintenanceWindow": "fri:09:00-fri:09:30",
"allowMajorVersionUpgrade": false
},Examining this call, we can see that this is why we are getting an error message — it contains a value for allocatedStoragebut not for iops.
Updating the parameter group
Notice that the modify call is also specifying the parameter group name. This is because the parameter group can only be specified for replica creation for Oracle DBs and we’re making an PostgreSQL instance. This means that the parameter group has to be added in a modification, which therefore means that the replica database will almost certainly need to be rebooted after creation in order to apply the parameters. Read the next installment of this series for more detail on how this works.
Module problem or provider problem?
Our module manages both primary and replica DBs, so it requires allocated_storage as an input. Even if it were managing only replicas, it would still have to allow allocated_storage since is possible to modify the storage of a replica to a different value than the primary.
We could change the module so that it doesn’t includeallocated_storage in the attributes for a replica, but this would mean that when we did want to increase the size of a database we would not be able to use the module to size up the replicas, so we ruled that out.
We could instruct our engineers to only set allocated_storage on a replica when they wanted to alter it (either through the module or directly using the aws_db_instance resource), but that is something that is easy to forget and we would certainly end up both:
- triggering the error again by setting the storage during creation
- having under-provisioned replicas by forgetting to add the
allocated_storageparameter to one of the replicas when increasing the storage on the primary
We first considered fixing the call to modify-db-instance to just include the IOPS, but this would not work because you cannot modify the allocated storage at all if:
- The instance is in the
storage-optimizationstate. - The storage has been modified within six hours.
When a DB is created, the first thing that happens is that it goes into storage-optimization, so the modify call would fail on that count. If the storage optimization was instantaneous, the call would fail because the storage had just been modified (created).
We concluded that it was best to submit a fix to the provider which does not try to modify the allocated storage after database creation, since this call simply should not be made.
We’re still waiting for the fix to be approved.
Module revisions

Managing dozens of PostgreSQL instances using several different versions of the engine and with many different workloads, it’s difficult to make a module that is everything every server needs. We’re on the fourth major revision of our RDS instance module now. We use it in about 50 stacks in our Terraform repository, covering over 100 database instances. When the version needs to be updated, it is a major undertaking to review all the plan changes, particularly if those changes involve adding new resources such as our DataDog monitors.
Large plan diffs increase the risk of making unexpected changes. EEven moree so when changes are being made in the console and not backported to the Terraform while at the same time changes are being made to the module. This means that some plan diffs are expected but some would be reversions, and it’s up to us fallible human beings to figure out which is which.
Module version updates are even more cumbersome when the inputs to the module change. With minor changes we can just do a find-and-replace on the module version. With API changes we have to go into each stack and update the attributes.
Module now/later/never?
In an ideal world, the module would be designed before your Terraform code base is large. The module would include all the necessary features on creation and would change very little. However the world is rarely ideal and sometimes it is important to encapsulate your best practices in a module even when those best practices are still evolving.
As a developer who is a fan of Agile development, I prefer to create modules earlier in the process and iterate on them, even at the cost of having to do many updates across all the stacks. Others prefer to push that work off until the code base is fairly static, but this leads to a lot of copy-and-paste which in turn leads to small inconsistencies accumulating with each copy.
In either case, you eventually have to make a number of passes over your repo to clean up these undesired deltas, so it’s a judgement call as to which method is best for your situation. I personally would recommend using modules early, even with all their drawbacks.
Come back soon to read about:
- Our struggles with parameter groups
- That time an abstraction bit us really hard
Want to work on challenges like these? Surprise, Instacart is hiring! Check out our current openings.

